지난번 게시물에서 가비지 컬렉터에 대해 작성하였는데,이번에는 C# .NET Framework의 VM(Virtual Machine)인 CLR(Common Language Runtime)에 있는 가비지 컬렉터는 어떤 작동 방식을 채택하였는지 알아보려고 한다.https://lms0408.tistory.com/3
.Net Framework GC에서는 세대별 가비지 컬렉션(Generation Garbage Collection) 의 기법을 사용한다.
이때 관리되는 힙(managed heap)은 총 3개의 세대로 나뉜다.
GC 0
0세대는 new(혹은 CreateInstance)를 통해 새로이 생성된 객체들을 일컫는다.
특정 조건이 만족하여 GC가 호출되게 되면 0세대를 대상으로 가비지 컬렉션을 수행하게 된다.
GC 0
0세대를 대상으로 가비지 컬렉션을 진행한 후 Compact 과정까지 마무리되면,
남은 객체들은 1세대로 승격하여 두 번째 힙과 같은 형태로 바뀐다.
그 이후 할당되는 객체에 대해서는 1세대와 별개로 다시 0세대로 분류가 된다.
힙에 0세대와 1세대가 공존하는 상황에서 또 한 번에 GC가 호출 시 0세대를 대상으로만 가비지 컬렉션이 진행되는데,
위의 그림에서 D객체가 더 이상 참조되지 않았음에도 불구하고 마킹되지 않아 유지된 것을 보면 알 수 있다.
가비지 컬렉션의 모든 과정을 마친 후 이전과 마찬가지로 0세대에서 유지된 객체들은 1세대로 승격되는 모습을 확인할 수 있다.
GC 1
1세대는 0세대에서 유지된 객체들을 일컫는다.객체가 쌓이고 쌓여 0세대 가비지 컬렉션을 수행하는 것만으로 메모리 공간의 확보를 할 수 없을 때,1세대의 하위 세대(0세대)를 포함해 가비지 컬렉션이 이루어진다.
GC 1
0세대와 마찬가지로 1세대에서 유지된 객체들은 2세대로 승격하게 되며,
그 하위 세대인 0세대 역시 다음 세대(1세대)로 승격하는 것을 볼 수 있다.
여기까지 확인함으로써 'GC X'는 X세대와 그 하위의 세대에 대해 가비지 컬렉션을 수행한다는 것을 알 수 있다.
그림을 보면 GC 1이 연속 2회 진행된 것을 볼 수 있다.하지만 GC 1이 연속 2회가 진행되는 것은 극히 드물다고 볼 수 있다.
GC 2
2세대 역시 1세대에서 유지된 객체들을 일컫는다.
총 3개의 세대(Generation)중 마지막 세대이며,
GC 2가 실행되면 2세대와 그 하위 세대들을 포함해 가비지 컬렉션이 수행되어 전체적인 메모리를 정리하기 때문에 Full-GC라고도 불린다.
전체 객체를 대상으로 GC를 수행하기 때문에 그만큼 시간이 많이 걸린다.
LOH(Large Object Heap)
LOH란 85000B(약 83KB)이상 상대적으로 큰 객체가 할당되어 관리되는 힙이다.
.NET Framework Garbage Collector에 대한 공식 문서에 따르면 2세대이나, 3세대라고도 정의하고 있다.
즉, 큰 객체에 대해서는 곧장 2세대를 가지고 할당된다는 것이고, 2세대 Managed Heap에서만 존재한다는 것이다.
LOH의 큰 특징은 Compaction을 하지 않는다는 것인데, 그 이유는 복사 비용이 크기 때문에 성능 저하로 인해 압축을 시키지 않기 때문이다. (.NET Core 및 .NET Framework 4.5.1 이상에서는 GCSettings.LargeObjectHeapCompactionMode 속성을 사용하여 필요시 압축시킬 수 있다.)
그렇기 때문에 LOH의 경우 C와 C++의 할당 및 해제 방식과 유사한 형태로 가비지 컬렉션을 수행한다.
LOH
위의 그림을 보면 가비지 컬렉션이 수행될 때 Compaction을 하지 않는 것을 확인할 수 있다.
새로운 큰 객체가 할당이 될 경우 수용 가능한 크기의 빈 공간에 할당되고 있다.
크기가 큰 객체의 잦은 할당은 GC 2를 더 자주 호출하게 되어 성능 저하가 발생할 수 있다는 것을 의미한다.
가비지 컬렉션 발생 시기
특정 조건이 성립이 되면 GC 0 ~ 2를 호출하게 되는데 어떠한 기준으로 GC가 호출되는지는 다음과 같다.
Excessive Allocation
메모리 할당이 일정 임계치를 넘어섰을 때 가비지 컬렉션이 발생된다.
0~2세대, LOH는 각각 버짓(budget)이라는 할당 임계치를 가지고 있다.
버짓은 고정된 값이 아닌 메모리 상황, 가비지 컬렉션이 수행됨에 따라서 지속적으로 변화되고 튜닝되는 값이다.
GC.Collect 메서드 호출
C#에는 GC라는 클래스가 있는데,
해당 클래스에 있는 Collect 정적 메서드를 호출함으로써 가비지 컬렉션을 임의로 발생시킬 수 있다.
Collect()
모든 세대의 가비지 컬렉션을 즉시 수행한다.
Collect(Int32)
0세대에서 지정된 세대까지 가비지 컬렉션을 즉시 수행한다.
Collect(Int32, GCCollectionMode)
GCCollectionMode 값에 지정된 시간에 0세대에서 지정된 세대까지 가비지 컬렉션을 수행한다.
Collect(Int32, GCCollectionMode, Boolean)
수집이 차단되어야 할지 여부를 지정하는 값을 사용하여 GCCollectionMode 값에 지정된 시간에 0세대에서 지정된 세대까지 가비지 수집을 강제로 실행한다.
컬렉션이 차단되고 압축되어야 할지 여부를 지정하는 값을 사용하여 GCCollectionMode 값에 지정된 시간에 0세대에서 지정된 세대까지 가비지 수집을 강제로 실행한다.
시스템 메모리 부족 상황
시스템 메모리가 부족한 경우 메모리 확보를 위해 프로세스에게 메모리 부족 상황을 알리는데,이때 CLR은 메모리 공간 확보를 위해 보다 많은 가비지 컬렉션을 수행하게 될 것이다.
Garbage Collection Modes
가비지 컬렉션이 어떤 스레드를 통해 작업이 수행되고,
수행되는 동안 CLR에 의해 관리되는 스레드(.NET 애플리케이션이 사용하는 스레드들)들의 중단(Suspend) 여부에 따라 크게 두 가지의 모드가 있는데, 그것은 바로 Workstation-GC, Server-GC이다.
또한 Workstation-GC는 다시 여러 부류의 모드로 나누어져 Non-Concurrent-GC 모드와 Concurrent-GC로 나뉘며 .NET Framework 4.0에서 새로이 추가된 Background-GC 모드도 있다.
Non-Concurrent-GC
Non-Concurrent-GC 모드는 가비지 컬렉션을 유발한 스레드에서 가비지 컬렉션을 수행한다.
이때 해당 스레드를 제외한 모든 스레드들의 작업은 중단(Suspend)을 하고 수행하게 된다.
Non-Concurrent-GC
위 그림에서 Thread 2에서 메모리 할당을 시도했을 때 메모리 부족으로 인해 가비지 컬렉션을 유발하였기 때문에 해당 스레드에서 가비지 컬렉션이 수행되고 있다.
이때 Thread 2를 제외한 나머지는 가비지 컬렉션이 모두 수행되기 전까지 중단되고 가비지 컬렉션이 모두 수행된 이후 작업을 다시 계속(resume)하고 있다.
가비지 컬렉션을 수행하는 스레드를 제외한 모두는 중단되므로,
가비지 컬렉션을 수행하는 시간이 길어질수록 애플리케이션이 정지되는 시간 역시 길어진다.
그렇기 때문에 많은 메모리를 사용하는 애플리케이션의 경우,2세대 가비지 컬렉션이 실행될 때 사용자의 경험이 좋지 않게 될 것이다.
Non-Concurrent-GC는 명시적으로 Concurrent-GC를 비활성화해주어야 사용할 수 있다.
Concurrent-GC
ConCurrent-GC 모드는 관리되는 스레드들의 중단 시간을 최소화하여 응답 시간을 향상하는 데에 중점을 두었다.
이 모드 역시 가비지 컬렉션을 유발한 스레드에서 가비지 컬렉션이 수행되고,
가비지 컬렉션을 수행하는 스레드를 제외한 모든 스레드들은 중단되는 방식이다.
여기까지는 앞서 알아보았던 Non-Concurrent-GC 모드와 별반 다를 게 없다.
Concurrent-GC
하지만 위 그림을 통해 알 수 있듯이 0세대, 1세대를 대상으로 수행하는 가비지 컬렉션의 경우 기존 방식과 같지만,
2세대를 대상으로 가비지 컬렉션을 수행할 경우 별도의 GC 스레드로 수행하며 다른 작업들도 수행하고 있는 것을 볼 수 있다.
2세대 managed heap을 가비지 컬렉션 하는 동안 다른 작업을 수행할 수 있는 이유는 새롭게 할당되는 객체들은 0세대에서 이루어지기 때문이다.LOH와 같은 큰 객체의 경우 2세대에서 할당이 되지만 LOH 힙은 Compaction을 수행하지 않기 때문에 할당과 메모리 정리를 동시에 진행할 수 있다.
따라서 비교적 빠른 GC 0, GC 1에 비해 GC 2를 별도의 스레드로 다른 작업과 함께 수행할 수 있기 때문에,Non-Concurrent-GC 보다 더 나은 사용자의 경험을 가져다줄 수 있다.
하지만 이런 Concurrent-GC도 한계가 있는데,2세대 가비지 컬렉션을 수행하는 도중 0세대 혹은 1세대 힙이 부족한 상황이 생겨 중첩되어 수행하는 경우가 발생할 수 있다.
이러한 복잡한 상황을 피하기 위해 CLR은 2세대 힙에 대한 가비지 컬렉션을 수행하는 도중 0세대 혹은 1세대 가비지 컬렉션 수행이 필요하게 된다면,GC 2를 제외한 모든 작업을 중단하여 가비지 컬렉션을 모두 수행 완료될 때까지 기다린 다음 다시 작업이 재개하게 된다.
또한 0세대, 1세대의 객체들이 2세대의 객체를 참조하고 있을 경우 2세대 힙을 Compaction 하는데 제약이 생길 수도 있다.이러한 경우는 2세대 가비지 컬렉션을 수행하는 도중 중간중간 잠시 동안 관리되는 다른 스레드들을 모두 중단하고 참조 값들을 업데이트를 할 수 있으며,때로는 Compaction 작업을 수행하지 않을 수도 있다.
이러한 이유로 인해 Concurrent-GC는 Non-Concurrent-GC보다 더 큰 힙을 구성하기도 한다.
Concurrent-GC 모드는 .NET Framework의 디폴트 가비지 컬렉션 모드(Default Garbage Collection Mode)이기 때문에 따로 설정을 하지 않는 이상 기본적으로 이 모드를 선택하게 되어있다.
BackGround GC
BackGround GC 모드는 Concurrent-GC를 대체하는 기능으로 .NET Framework 4.0에 새로이 도입된 Workstation-GC 모드이다.
기존 Concurrent-GC의 경우 2세대 힙을 정리하는 동안 0세대 혹은 1세대의 가비지 컬렉션이 발생할 수 없었다.
그러나 BackGround GC의 경우 2세대 힙을 정리하는 동안 0세대 혹은 1세대의 가비지 컬렉션을 수행할 수 있도록 되었다.
BackGround GC
BackGround GC는 2세대 가비지 컬렉션이 수행되는 도중 0세대 혹은 1세대 가비지 컬렉션이 필요하게 된다면,
2세대 가비지 컬렉션을 잠시 중단하고 0세대 혹은 1세대 가비지 컬렉션을 우선적으로 수행할 수 있도록 한다.
그렇기 때문에 Concurrent-GC에 비해 애플리케이션의 응답 시간이 전반적으로 좋아질 수 있다.
하지만 그만큼 스레드들 중단이 자주 발생할 수 있으며, 좀 더 큰 힙이 구성되기도 한다.
Sever-GC
Workstation-GC 모드와는 다르게 시스템 상의 프로세서 개수만큼 관리되는 힙을 만들고, 관리되는 힙의 개수만큼 가비지 컬렉션 스레드가 생성된다.
예를 들어 헥사(6) 코어에 하이퍼 스레드가 적용된 컴퓨터에는 12개의 관리되는 힙이 생성되고, 그 개수만큼의 가비지 컬렉션 스레드가 생성된다는 것이다.
이렇게 프로세서마다 고유의 힙을 생성하는 이유는 메모리 할당의 병행성을 높이기 위해서이다.
WorkStation-GC의 경우 2개의 스레드가 동시에 객체를 생성하고자 할 때,
힙이 1개만 존재하므로 어느 한 스레드가 메모리를 할당하는 동안 다른 스레드는 이를 기다려야한다.
반면 Server-GC의 경우 각 프로세서마다 고유의 힙을 가지고 있기 때문에 병렬적으로 메모리를 할당할 수 있다.
프로세서마다 존재하는 힙은 서로 다른 힙에 대한 참조를 가질 수 있으며, 별 다른 제약을 가지고 있지 않다.
또한 힙 마다 할당된 고유의 가비지 컬렉션 스레드가 힙을 정리하기 때문에 좀 더 빠르게 힙을 정리할 수 있다.
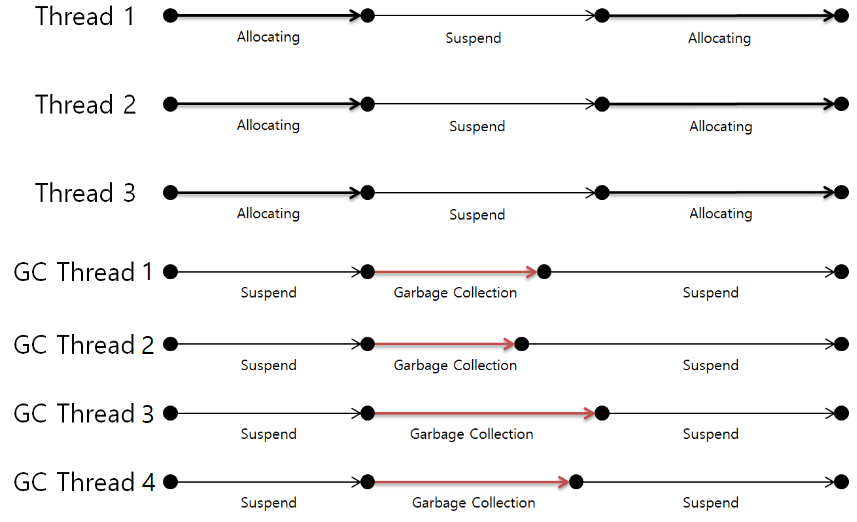
Server GC
위 그림의 예시는 4개의 논리 프로세서를 가진 시스템에서 수행되는 Server GC이다.
프로세서의 개수만큼 GC 스레드가 생성이 된 것을 확인할 수 있다.
가비지 컬렉션을 수행할 때는 다른 작업 스레드들은 모두 중단이 되며,
각각의 GC 스레드는 작업을 완료하는데 소요되는 시간이 다를 수도 있기 때문에
모든 GC 스레드의 작업이 완료되어야 다른 스레드들이 작업을 재개할 수 있다.
논리 프로세서마다 고유의 힙을 만들어 병렬적 수행이 가능해 힙을 상대적으로 빠르게 정리할 수 있다는 장점이 있지만,